- Published on
Tensorboard Enhancement
- Authors

- Name
- Sunway
- @sunwayz365
系统架构
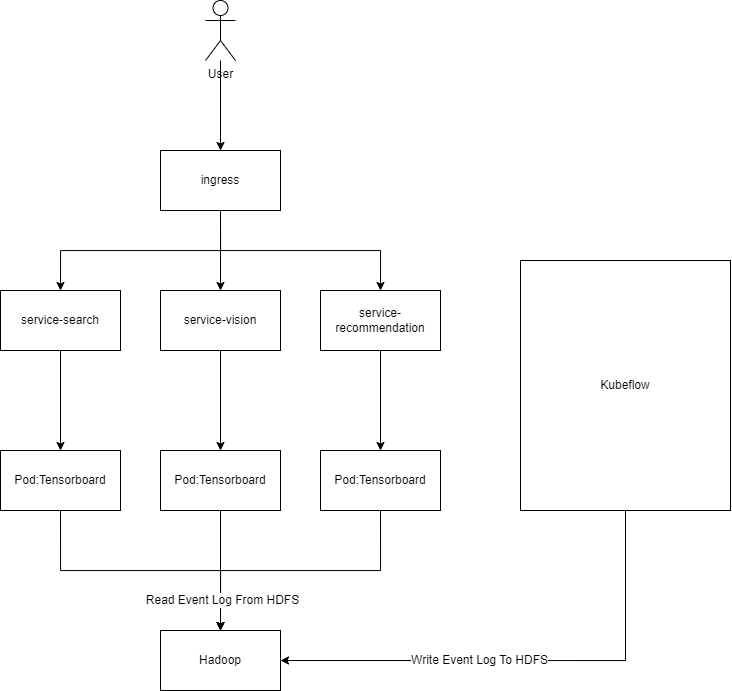
Tensorboard 服务根据算法团队的不同业务需求被分为多个独立的 service,包括搜索团队、视觉团队、推荐团队等。
算法团队通过 Kubeflow 进行模型的训练和部署,并通过 TensorFlow/PyTorch 的 callbacks 机制将 event log 写入 HDFS 根目录下的不同子目录中。
不同算法小组的 Tensorboard 服务通过指定不同的 logdir 参数,从 HDFS 的相应目录读取 event log 并进行实时展示。
问题描述
HDFS 与 Tensorboard 数据展示不同步是主要问题。
例如,当 HDFS 中存储了从 1 到 1000 的 event log 时,Tensorboard 的界面上却只展示到了 950,导致最新的 50 条 event log 无法及时显示。
这使得算法团队在训练新模型时无法实时查看模型指标,不得不通过堡垒机使用 hadoop fs -get 命令获取数据,然后在本地启动 Tensorboard 进行查看,整个流程十分繁琐。
问题排查
通过 hadoop fs -du 命令发现,多个 HDFS 子目录下的 event log 堆积严重,基本都达到几百 GB 以上,最高的一个目录甚至超过了 1 TB。
这种大量数据堆积导致 Tensorboard 读取 HDFS 文件出现延迟,造成 Tensorboard UI 显示滞后。
虽然 Tensorboard 服务是通过 Helm Chart 部署的,Pod 监控显示 CPU 和 Memory 使用无明显异常,但数据同步问题依然存在。
解决方案
调整 Tensorboard 启动参数
1 修改Tensorboard启动参数:--max_reload_threads
The max number of threads that TensorBoard can use to reload runs. Not relevant for db read-only mode. Each thread reloads one run at a time. (default: 1)
将其修改为4,使用4个线程去拉取增量数据
2 修改Tensorboard启动参数:--reload_interval
How often the backend should load more data, in seconds. Set to 0 to load just once at startup. Must be non-negative. (default: 5.0)
将间隔调整为 30s,减少 tensorboard 向 hdfs 请求增量数据的频率
修改Helm Chart 配置
**提高 cpu.request,删除 cpu.limit **
根据 pod 监控统计,tensorboard cpu usage 还是比较稳定的,没有出现过 CPU 飙升影响宿主机上其他服务的情况
于是将 pu.request 改为 4 且删除 cpu.limit 配置,因为 centos7 内核版本 3.x 有Bug , 在有 cpu.limit 参数的情况下会触发throttling节流
该Bug在内核4.19已修复
定时任务
因为观察到文件夹太大的原因,所以用 springboot hadoop 客户端实现一个 cron job(没有用宿主机的cronjob的原因是担心机器下线或迁移,运维团队不想维护这个东西),定时删除堆积的event log,只保存30天内的数据
一套折腾下来后,tensorboard 服务稳定,hdfs 和 tensorboard ui 数据实现了同步